“The Crown Jewels are the ceremonial treasures which have been acquired by English kings and queens, mostly since 1660.
The collection includes not only the regalia used at coronations, but also crowns acquired by various monarchs, church and banqueting plate, orders, insignia, robes, a unique collection of medals and Royal christening fonts.”
www[.]royal[.]uk
According to the site Readers Digest, the British Crown Jewels are worth somewhere from $1.2 to $5.8 billion. The Crown Jewels are comprising more than 100 objects and over 23,000 gemstones. The Crown Jewels are priceless, being of incalculable cultural, historical, and symbolic value. The Crown Jewels are part of the Royal Collection, held in trust by the monarch for the nation.
As they have such a high value, during the Second World War the jewels were hidden in a secret location that has never been disclosed. They were protected with adequacy to their considered value.
Every organization has its own Crown Jewels. In today’s time age, the Crown Jewels for most organizations and nations have switched from physical to digital assets such as for example intellectual properties, proprietary information, patents, and similar. The current substrate we live in is called <*DRUMROLL*> the digital information age.
During the last 2-3 years, since this article was written, 90% of the digital information available has been produced. And we are just in the beginning. Machine learning, AI, and quantum computing for example are still in their very early evolutionary cycles and will be contributing to future growth.
If information is considered important now, things will become very interesting as we become increasingly digitalized. We are, as I just said, in the very beginning of things. And we, as organizations/humans/society/security professionals, do not always contemplate how important digital assets are to ourselves as individuals or to our organizations.
THE CHALLENGE
As mentioned in the prologue, digital assets (such as example data and information) are today considered highly valuable assets for organizations. Information is today one of the major drivers of both qualitative and economic growth.
Almost every organization is today in one way or another digitalized and interconnected. And every organization has its own Crown Jewels, i.e. those digital assets that are considered highly valuable and sensitive to the organization.
As digital assets such as, but not limited to, data and information increase in growth on both a global scale and within the organizations it becomes more and more important to understand which digital assets that are those Crown Jewels. To protect the organization, the digital assets within the organization need to be adequately protected.
When I say “adequately protected” I mean that the digital assets need to be protected according to the value, sensitivity, and criticality of the organization.
Some people say that digital assets need to be protected based on their “requirements” and “risks”. For me, that is a part of value, sensitivity, and criticality. In any case, the words we put into it are less important. The important thing is to make sure the assets are protected in relevance to how important they are determined to the organization.
Information classification can be seen as a risk assessment methodology conducted from an asset-centric perspective. All digital information assets do not carry the same value, sensitivity, and criticality. Keep this in mind! This is a critical thing to continually keep in mind when it comes to the discipline of Information Classification. I will come back to this several times through this article and in the future once. And after you have read this article you will understand why.
If you and your organization do not know what Crown Jewels you have in your organization and where they reside (business processes, information systems, supply chain etcetera). How will you and your organization, for example, be able to:
- understand the asset value if you can not and do not identify them?
- protect your digital assets if you do not know where they reside?
- protect the assets throughout their lifecycle (creation, changes, and deletion) if you do not manage them systematically?
INFORMATION CLASSIFICATION
Information classification is very similar to risk management but conducted from an asset-centric point of view. One of the first actions that are to be conducted during a risk assessment is to identify the asset related to the risk and targeted by the threat actors. Those who are experienced in risk management, I have found, will pretty easily understand the purpose and concepts of information classification and how it is conducted.
If you are interested in risk management and want to read a word or two about the subject from my point of view, I recommend you start out with this article: What is Risk Management.
But just to clarify, information classification or risk management is not rocket science. There is no requirement to be a risk management expert to understand the information classification discipline.
The Information Classification process, compared to the Risk Assessment process, is linear. The process is following a certain order and is not nonlinear compared to the Risk Assessment process.
One of the more common misconceptions that I have run into is that Information Classification often gets misunderstood and made equivalent to Information Protection.
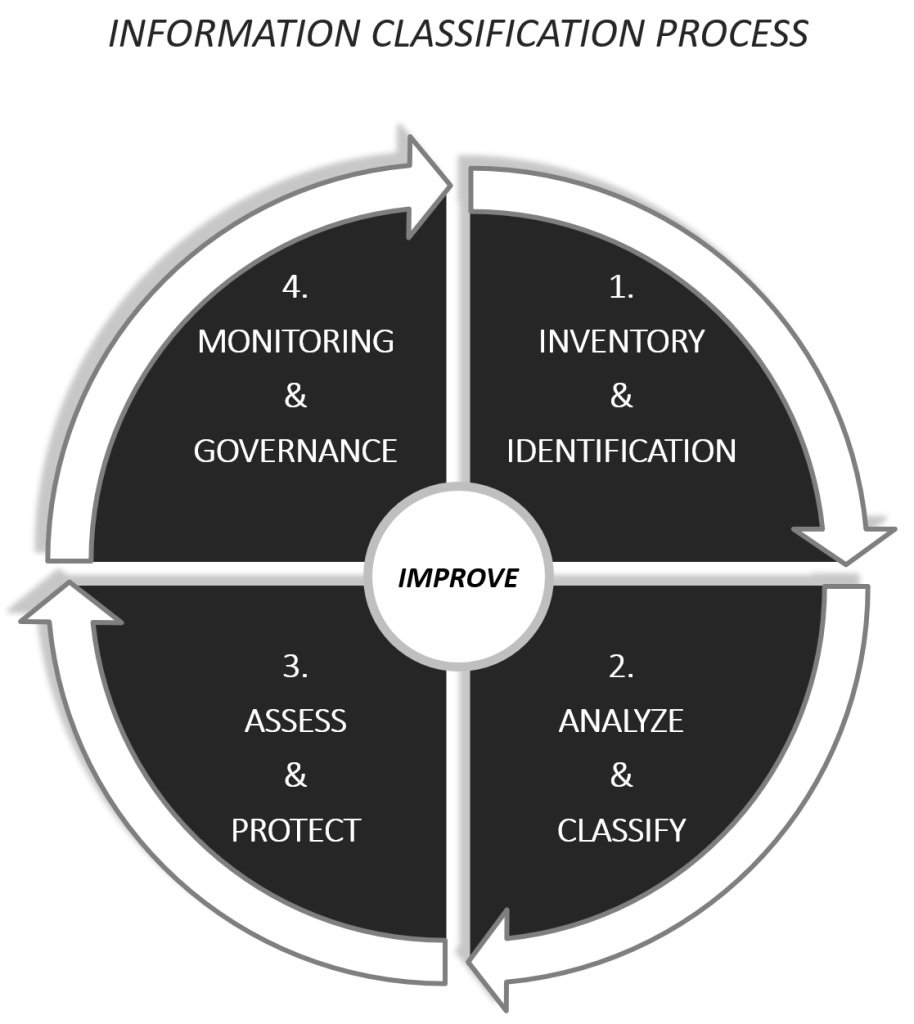
Information classification is the discipline. Information protection can be seen as one of the phases within the discipline, i.e. Assess & Protection. Figure 1 below illustrates what I just explained.
A key success factor to achieving a sustainable information classification within your organization is to educate the Humans. Explain to them why the digital assets shall be classified. And explain to them how it is done.
In the first portion, explaining the “Why”, I usually use an analogy. Further down in this article, you will find one that you can use and that I have used several times successfully. The more time you spend on this part, to explain the “Why”, will be well invested. Trust me. One of the reasons for it is due to that the crown jewels within the organization will shift if shape and character between business units.
The other part, the “How”, is coupled with having good and easily understandable steering documents, guiding principles, processes, and methodologies in place. Guiding documents that describe how things are done by providing applicable examples and scenarios relevant to the stakeholders and their business.
One of the core elements, related to information classification, is to have a guiding methodology in place. This is usually a matrix. This is though not the only thing you need…but I have seen, here and there at some places, that information classification sometimes stops here. There is no further support or guidance provided around the discipline. And a matrix (whether it is used for information classification or risk management) will not be enough. I will mention a couple of words about that “matrix”.
THE MATRIX
An information classification matrix shall contain the labels and guide the information owner to choose the adequate label. The label will dictate how the asset shall be protected (when security controls are applied in the Assess & Protect phase).
Figure 2 is a visual illustration of an information classification matrix. This one is just an example. The labels and matrix shall be designed and developed according to your organization’s security requirements.
Some of the things to take into consideration when designing an information classification matrix are:
- Internal security and compliance requirements
- External security and compliance requirements
- Regulations, laws, and requirements from authorities
- Quality requirements
- Business impact
I strongly recommend starting out easy, do not make something that is complex or that contains loads of levels. Try to give the names of the labels that are easy to understand and that resonate with how you speak and communicate in your organization.
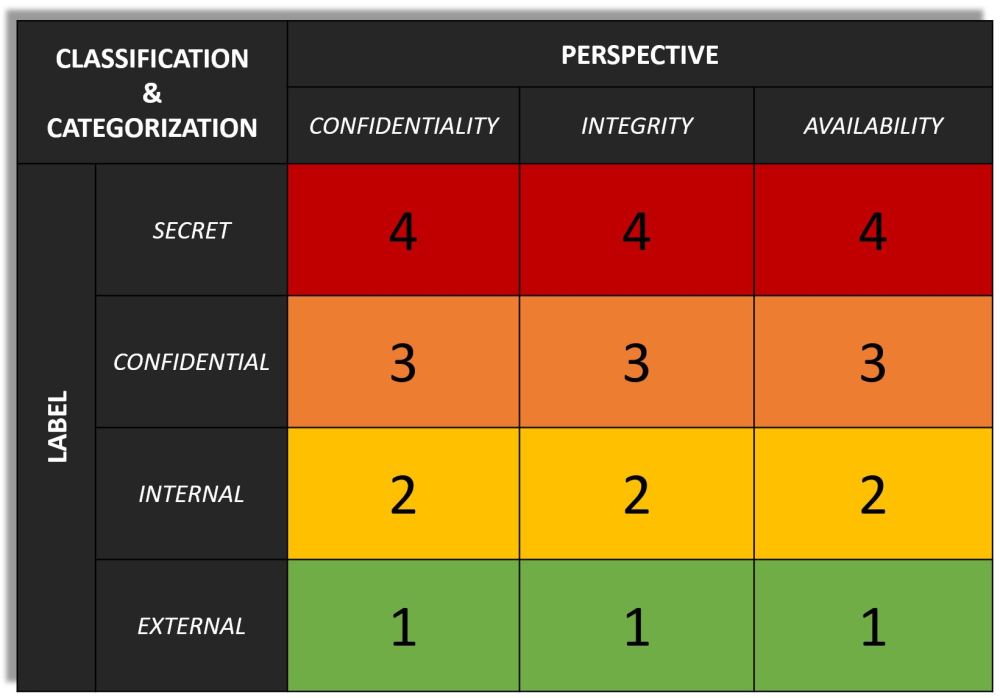
NOTE! This is just an example. The content and how “the matrix” is constructed need to be based on the requirements of the organization it serves.
If for example, the term secret is not a word that is used, I recommend choosing another one. Keep the naming, guiding, terms, process, and things easy. Make it easy to understand.
If it is not easy to understand you will lose the effects. The assets will not be classified. The value from the information classification discipline, processes, model, guiding principles etcetera will not be realized to its full effect. I have seen this take place too many times. An information classification project to become a technical IT project.
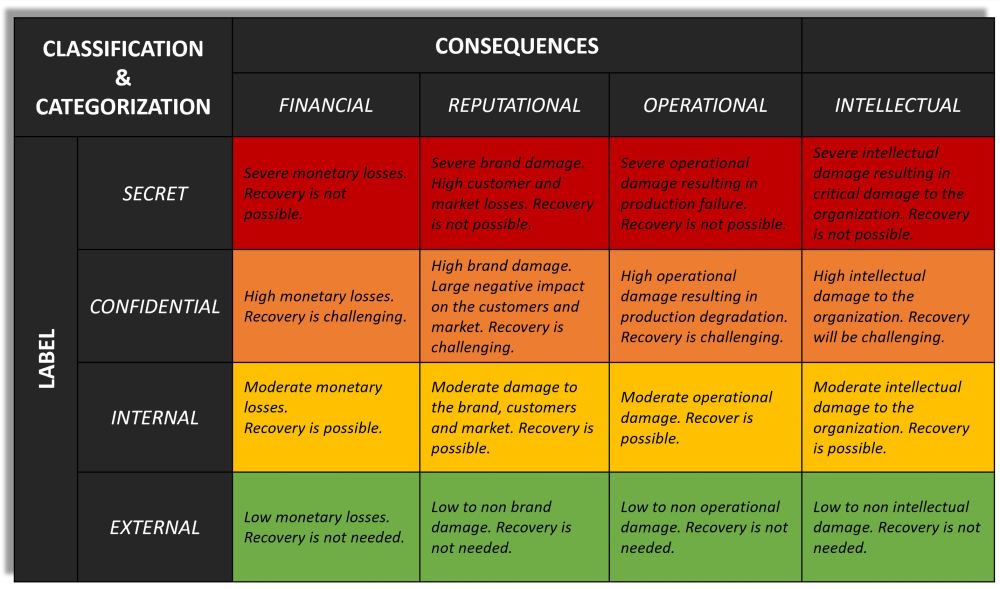
NOTE! This is just an example. The content and how “the matrix” is constructed need to be based on the requirements of the organization it serves.
I wrote about the CIA triad in this article, The CIA triad made practical. The CIA triad can be one tool used, in the information classification process, to guide the classification of the asset.
This does not need to be the case though. But many organizations use the CIA triad in this way and within the information classification discipline. Yes, the CIA triad has its limitations. But as said, use it for guidance and be pragmatic. And it will take some time before it fades away and something else will be replacing it.
Personally, as the CIA triad is limited it is a good idea to add further perspectives to it and to use a consequence model along the road. Another good idea could be to dictate certain security controls that are mandatory if an asset falls into a certain category. So-called information management rules and principles. I know that certain standards, theories, and practices say that this is not how things shall be done though. The output from the information classification process shall be used as a requirement to decide on which security controls shall be applied. The output shall be used to dictate security requirements that the IT security teams apply.
But as I said, be pragmatic. And do those things that are practical. The information classification is there to enable the assets to be protected. Take this into consideration and think about the information classification from this perspective. If the process becomes complicated and too advanced, with for example too many if-statements and bureaucratic sh*t the chances are that the effects will be reduced. I have seen this take place more than once. Keep it simple and take the following into account when going forwards.
#PRAGMATISM
The Phases
An Information classification process includes several phases. Different frameworks, standards, and academies might name them a little bit differently compared to my naming below or contain additional phases.
If you are studying for a certain certification or exam, which body of knowledge includes the subject Information Classification, make sure to understand the phases and the process according to that framework, standard, and academy. In general, the activities within the process and the phases are the same though.
I try to stick to four phases when I construct an Information Classification process. The reason for this is that I have found that this is what has been the most practical and effective way of doing things. Nothing wrong, according to myself, if there are five or six phases. But if the process, for the Information Owner, visually looks “large” it might also be generating overwhelming feelings. Try to keep it slimmed. Both in terms of how it is presented and also in the actual and practical application of the work, i.e. when the information is to be classified.
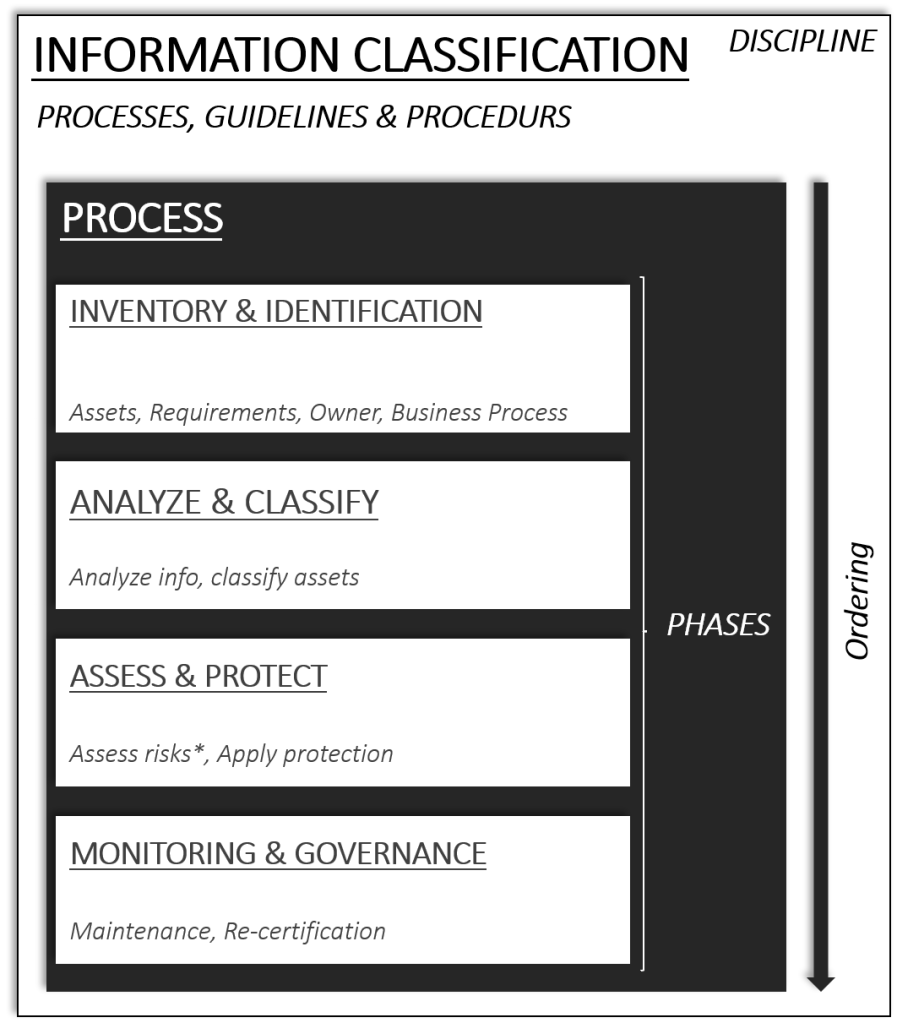
I will explain each phase very simply and what the purpose of each one is. I will not go into deep dives of each phase in this article.
Another reason why I think a process that includes fewer phases, for example where phases are combined or condensed, will lead to it becoming easier to understand and learn. The stakeholder, i.e. information owner for example, of the process “only” needs to remember those four phases. That old saying, keep it simple. This is very applicable to the information classification discipline. Too often things are over-complicated and also start in the wrong place and phase. But more on this later in this article.
INVENTORY & IDENTIFICATION
During this phase of the Information Classification process following activities are conducted:
- Inventory and identification of the assets that are to be classified.
- Assign asset owners, also known as Information owners.
- Identification of stakeholders that has knowledge of the asset value, sensitivity, criticality, and other relevant information. Such as for example: where is the information stored, information systems, compliance, and security requirements.
ANALYZE & CLASSIFICATION
During this phase of the process following activities are conducted:
- Analyze the information from the previous phase.
- Classify and label the information based on the analysis.
ASSESS & PROTECT
During this phase of the process following activities are conducted:
- Assess the requirements and results from the previous phase.
- Apply adequate security controls to ensure the assets are protected based on their value.
MONITORING & GOVERNANCE
During this phase of the process following activities are conducted:
- Ensure protection of the asset is, in a continuum, maintained.
- Conduct re-certification of the asset to ensure the classification of the asset is relevant to its value determined by the organization and asset owners.
IMPROVE
This part is not a phase. This part of the Information Classification process is something that I personally strongly believe in, which is to ensure the model, guiding principles, processes, and methodologies are continually developed. And improvement is for me what security is all about. It is an infinite and continuous journey.
This phase includes for example:
- Systematically and periodically improve the discipline.
- Educate stakeholders about information classification.
- Conduct security awareness related to information classification.
- Integrate the information classification into other critical business processes, for example, the procurement process.
ANALOGY
All the things that we own personally do not hold the same value to us and our families. The assets we have at home, in our basement, in our garden, and in the garage all have different values. I am stating the obvious here but it will make sense, hang on there.
Have you, reading this, done your asset inventory and categorized the assets? Do you know and have you determined which of these assets are the most important for you and your family? Is it those old photos that you only have a physical copy of for example? Or is it those old paintings? Or those gold bars? Only you and your family know.
You, who own these assets, are the asset owners. And only you might be the person who actually knows where the assets reside. It is less good if the thieves know where you store your most valuable assets.
A bad idea might be to express that on social media…or even to say “Hey, we are going to be in Aruba for 4 months!”. This is equivalent to saying, “Hey, we will not be home and the castle will be unguarded.” This is also something that insurance companies will see as less good behavior that may implicate if someone breaks into the house and steals your assets and crown jewels.
Let us assume you have four different ways how to store your assets. The ways how to store the assets are equivalent also how to protect them. Translating the storage of assets to information classification equals security controls, i.e. how they are protected. You have constructed a model that contains categories.
- High – Equivalent to secret. For example gold bars, jewels, secrets, exclusive art, testaments etcetera.
- Medium – Equivalent to confidential. For example, passports, personal furniture, electronic equipment, musical instruments, personal items, etcetera.
- Low – Equivalent to internal. For example, old items are no longer used at home. Old equipment, computers, furniture, electronic equipment, toys, sports equipment etcetera.
- None – Equivalent to public. For example garden equipment, towels, forks, spades, garden furniture, etcetera.
As you have understood by now, if you have been reading one or more of my articles, I like to simplify things through models and analogies. The above description gives us the following visual composition.

The stuff, described above, is all assets. And they do not hold the same monetary value. Of course, if you as an owner decide everything is equally valuable to you, they should be protected in the same way. In the same place.
But let us play a game here. If the stuff in the “Non” and “Low” category would be categorized as “High” instead. That would mean that the things should be moved into the secret room. But keep this in mind here. The secret room, inside the house which is the place with the highest security and protective measures, only has limited space. We can translate this, i.e. “limited space” to “limited resources” in the corporate world. If every asset would be protected in the same way, not only for sure, costs will follow. They will increase.
Applying real-time monitoring for changes on all digital assets within an organization is absolutely something that can be done. But I have a hard time seeing the actual business case as every asset does not hold the same value. They are not as critical or sensitive to the business landscape or organization as such.
If Johnny stores some cat and dog pictures on his PC, under C:\Johnnys_Local_Files\Cat and Dog Pictures, he chooses to make some changes to them. Or he copies them to a USB. Or send them via e-mail to a friend or posts them on Facebook. Is there something that needs to be real-time monitored? No. These things are of course important and valuable for our guy Johnny who likes cat and dog pictures…and so do I. The fact is that I am a huge animal person who loves dogs and cats.
My example is a bit polarizing as I go to the total outer end of the scale in this example. But the thing here is that this example is something that some organizations live by. They go with the idea of “Let’s encrypt everything!” or “Let’s secure every digital asset in the same way.”. That is possible, but it is not sustainable. That is not how you want to do it. That is not how you capitalize on information classification. I think you get my point here.
EPILOGUE
Do you have an understanding of what digital assets are your own and your organization’s crown jewels and where they reside? It all starts there.
You can not protect what you can not identify. And you can not determine the value of the asset if you do not know if it exists.
If I would be allowed to give only one security recommendation to any organization, this is it. Asset management and inventory. Getting an understanding and good management of your assets will enable that many fundamental security issues will pan out much easier for you and your organization. You can not protect what you can not identify.
Back in the days, when I started out my career, the technological tools for information protection and label assignment were limited. The solutions out there provided low functionality and it was more about manually making the magic happen. Assigning labels, inventory of assets, data loss prevention rules and policies, and so forth. This stuff, that I am talking about right now, was also back then (and still is) here and there called and spoken about as Digital Rights Management.
Now, when the year is 2023, and a couple of years back, things have changed tremendously! Information protection technologies do not only provide high interoperability and integration with everyday office working tools, like the Microsoft Office suite and collaboration capabilities (SharePoint and Teams). Some of these capabilities have machine learning and automation built in. The technologies do not only identify assets based on certain conditions, but they also help you and your organization to automatically enable protective measures.
The thing though, that happens here and there is that these Information Classification projects become driven by a technocratic agenda and mindset. Many projects start directly in the “Assess & Protection” phase, but skip the assessment part and go directly to “Protection”. They go straight out and apply security controls in terms of protective measures. This is OK, nothing wrong here as long as you are understood that the effects are left out. You have not achieved or conducted the essence of Information Classification. You and your organization skipped the most critical phase in the discipline.
Some of the things that have been left out are:
- Understanding the value of the asset.
- Construction of an information classification model.
- Development of guiding principles and steering documents.
- Communication with the stakeholders and education of the information owners.
- Creating security awareness.
Information classification is something that is very closely related to the organization. This is not an IT or technological discipline. The reason for this is <*DRUMROLL*> the information owners (in most cases) reside in the business. It is the person who is working with that balance sheet, patent, intellectual property etcetera who knows the value of the asset, i.e. digital information, data, business process etcetera.
The technical “IT-security stuff”, i.e. information protection and security controls implementation, is a part of the information classification discipline. And the protective measures and security controls shall be applied and based on <*DRUMROLL*> the requirements from the information owner, who understand the value of the asset. And to support this, the information classification discipline, uses a matrix, guiding principles, steering documents, end-user communication, training, and so forth.

The governing and guiding documents, matrix, models, processes, and so forth, according to how I see things, shall provide that –> “Guiding”. If the matrix, process, model, and document will becomes too complex I think that the value is less likely to be realized. The methodology for classifying and labeling information needs to be easy to understand.
Personally, I like to create principles instead of absolute terms IF those absolute terms are not possible to be created. In certain industries, due to for example regulations and laws, certain information needs to be classified according to specific requirements. But this is not something that applies to every and each organization. Keep this, what you just read, in mind when crafting your information classification <things> for your organization.
Information Classification is about classifying information assets according to the value to the organization, dictated by the Information Owner. The classification will determine how the digital asset shall be protected, i.e. which and what types of security controls shall be applied.
recommendations
Know your organization’s crown jewels. A crown jewels for your organization might not be the same as for another. Make sure to understand what carries the highest value in your organization. Crown jewels come in many different forms.
Keep things simple. The label names, processes, methods, guiding principles, and the matrix. Yes, as much as possible as simple as possible. Strive for taking a pragmatic approach.

Use acronyms and terms that are easy to understand. Craft the material, label names, communication material, and awareness training in the language for how people speak about assets and security in your organization.
Improve as you go. Start where you are and improve along the road. If the information classification model is not 100% perfect on day 1, that is OK. Strive for starting out and testing, refining, tuning, and adjusting it along your organization’s journey as you learn more about what works and does not work.
Henrik Parkkinen
